



Компания HeadHunter давно занимается онлайн-рекрутментом, то есть, опираясь на технологические и информационные возможности интернета, предоставляет людям возможность найти подходящую работу, а работодателю — нужного сотрудника. Недавно HeadHunter объявила, что внедрила «умный» поиск вакансий, основанный на использовании машинного обучения, или искусственного интеллекта. О том, что это означает для самой компании и прибегающих к ее услугам соискателей и работодателей, «Эксперт» попросил рассказать Бориса Вольфсона, директора по развитию HeadHunter, который, собственно, и занимается проектами, связанными с высокотехнологическими разработками, в частности с искусственным интеллектом.
— Какие преимущества вам как компании, занимающейся интернет-рекрутментом, дает использование искусственного интеллекта?
— Наш бизнес на самом деле очень простой. Мы умеем грамотно находить в интернете, а в последние несколько лет и в офлайне людей, ищущих работу или просто мониторящих рынок труда, чтобы понять, сколько они стоят, и привлекать их к нам на сайт. Какая-то их часть в итоге откликается на вакансию, получает приглашение от работодателя и устраивается на работу. Соответственно, у нас есть два показателя, отражающих эффективность бизнеса. Первый показатель: сколько всего людей мы привлекаем, то есть численность нашей аудитории в целом. Для этого организуется рекламная кампания по цифровым каналам, в офлайне, в первую очередь по телевидению, но и на билбордах тоже.
Второй показатель: как мы эту аудиторию конвертируем в отклики на вакансии. Ведь фактически работодатели покупают у нас именно отклики, оплачивая каждый клик на объявление. Здесь важно максимально облегчить человеку поиск нужной именно ему вакансии. До недавнего времени у нас этот поиск работал самым примитивным образом, как, впрочем, это происходит до сих пор на рынке в целом. Вы вбиваете название профессии, создаете несколько фильтров, и из базы вам отсеиваются вакансии, соответствующие этому запросу. Так работают все джоб-сайты. И если более широко взять, то так работают абсолютно все классифайд-бизнесы — продажа и аренда недвижимости, автомобилей и прочее. И от того, насколько качественно мы покажем пользователю объявление, зависит процент конвертации, то есть доля аудитории, которая кликает по объявлению.
— Вы хотите сказать, что когда вы ввели в процесс искусственный интеллект, этот показатель вырос?
— Да. Но давайте я все же два слова скажу о технологии, чтобы стало понятно, как это работает. То, что я описал, называется «полнотекстовый поиск с фильтрами». С одной стороны, это стандарт для рынка, все вроде бы работает достаточно хорошо. Но есть проблемы. Например, вы врач-стоматолог и хотите найти работу на обычном джоб-сайте. Логично вбить слово «стоматолог» в поисковой строке. Но часть вакансий, которые вы увидите, будут совсем не вакансиями стоматологов, а вакансиями, где в условиях работы указан полис ДМС, куда включена стоматология. Или другой кейс. Вы менеджер проекта. Вы можете ввести в поисковом запросе слово «менеджер», но удивитесь, не увидев заявок на менеджеров проектов в поисковой выдаче. В основном вы увидите в ней «менеджер по продажам», поскольку это одна из самых востребованных специальностей.
Получается, пользователю в общей массе показывают и те вакансии, на которые он никогда не откликнется. И мы решили эту ситуацию поменять.
— Каким образом?
— Сначала небольшая предыстория. На самом деле интерес к искусственному интеллекту у нас начался давно — года три-четыре назад, как, впрочем, у многих на рынке. Начали мы с пилотных, «игрушечных» проектов. Например, по тексту резюме научились понимать, какими навыками и компетенциями обладает человека, и в специальном поле стали давать ему подсказки. Но в отличие от многих наших конкурентов мы в итоге осуществили масштабный проект, касающийся основ нашей работы: в корне изменили с помощью искусственного интеллекта систему модерации резюме.
— Что такое модерация резюме?
— Когда соискатель у нас создает резюме, оно обязательно попадает к модератору. Это человек, проверяющий смысл резюме, — у него есть определенная инструкция, алгоритм. Например, надо определить, соответствует ли должность, на которую претендует соискатель, опыту его работы, и забраковать резюме, если одно противоречит другому. Это необходимо для того, чтобы обеспечить качество нашей базы соискателей. Поскольку у нас аудитория растет, количество модераторов нужно увеличивать. Для бизнеса это не очень хорошо, потому что растут расходы на персонал. И в какой-то момент мы поняли: все, что делают модераторы, можно обсчитать и понять, как они проверяют резюме. И заменить их машинным обучением или искусственным интеллектом, если говорить более широко.
— То есть, анализируя работу модераторов, вы выявили критерии, по которым подбирается нужное резюме?
— В данном случае речь идет не о подборе, а о проверке, хорошее оно или плохое. И сделали мы это очень просто: у нас на тот момент было двадцать с чем-то миллионов подтвержденных резюме. И количество неподтвержденных резюме тоже исчислялось миллионами. То есть мы знали, каким резюме модераторы говорят «да», а каким — «нет». Это можно назвать большими данными, биг дата пресловутыми. Мы их «засунули» в систему машинного обучения, и она научилась на примере истории принятых решений говорить новым резюме «да» или «нет». Можно, конечно, написать для процедуры проверки алгоритм, но это сложновато. А искусственный интеллект с такими задачами справляется на раз. При этом мы подбирали порог чувствительности так, чтобы качество модерации нашей системы на искусственном интеллекте было неотличимо от качества модерации живых модераторов. У нас получилось один в один.
В итоге две трети резюме у нас автоматически подтверждаются. И нам нужна только треть того числа модераторов, которое было бы необходимо, не включи мы искусственный интеллект. Они заняты тем, что рассматривают сложные, нестандартные случаи. Вот и экономический эффект — сокращение потребности в персонале.
Слияние смыслов в одной точке
— Но что все-таки с увеличением числа откликов? Как в этом случае работает искусственный интеллект?
— Это уже второй шаг. Подход был примерно таким же. Мы опять решили использовать машинное обучение для того, чтобы соискателю не попадались нерелевантные вакансии. У нас ведь гигантское количество информации по откликам: какие резюме откликались на какие вакансии. Это уже биг дата классические: в базе сотни миллионов элементов. То есть мы отбирали вакансии не просто по наименованию профессии, но и научились их ранжировать по вероятности, с которой соискатель откликнется на вакансию. Для этого используются уже не пять-десять простых фильтров, а несколько сотен. Например, очень хорошо играет сравнение поля зарплаты в вакансии и резюме. И чем больше они отличаются, тем ниже вакансия будет при прочих равных ранжирована в этом списке.
Помимо числовых мы проверяем и текстовые поля, но не полнотекстовым поиском, а стараясь понять смысл того, что написано. Для этого есть специальные подходы, превращающие слова в точки в многомерном пространстве. Проще говоря, можно представить двухмерную плоскость, где близкие слова по смыслу будут находиться рядом в виде точек. При этом они могут не иметь общих корней, букв, без чего традиционный полнотекстовый поиск дает сбой. Например, «разработчик» и «программист» должны сойтись в одной точке. И, знаете, сама система научилась понимать, что слова «отоларинголог» и «ЛОР-врач» по смыслу одинаковы. Мы ее не учили, но она поняла.
— Каким образом?
— Очень просто: люди с резюме отоларинголога откликаются на вакансии ЛОР-врача, и наоборот. Понятно, что при таком подходе у нас получились хорошие результаты. Число откликов выросло на десять процентов. У нас этот проект занял около девяти месяцев. Точную сумму инвестиций в него мы не называем, но это несколько десятков миллионов рублей. Это включая стоимость «железа», ведь большие данные надо где-то хранить, где-то обрабатывать, так что нам пришлось нарастить серверный парк.
И давайте я еще про финансовый результат добавлю. Я рассказал, сколько мы потратили. А сколько мы заработали? Чтобы это подсчитать, мы в этом проекте сделали еще одно интересное упражнение: научились понимать, сколько денег каждый дополнительный отклик приносит компании. Для этого мы сделали модельку, тоже на машинном обучении, и связали количество откликов, которые получает работодатель, с оттоком работодателей. У нас ведь работодатели работают по подписной модели: если они удовлетворены, то подписываются дальше. И мы через отклики, то есть через качество оказания услуги и через отток, подсчитали, сколько нам это приносит денег. Это на самом деле нетривиальная задача была. Я не слышал, чтобы кто-то так делал.
— Кто больше готов быть вовлеченным в усовершенствованный искусственным интеллектом рекрутмент — работодатели или соискатели? Кого вы видите своей аудиторией?
— Что касается грамотности и технологизированности, то аудитория соискателей более адекватна, чем работодатели. По факту HeadHunter уже не столько сайт, сколько мобильное приложение и мобильный сайт для соискателей: им можно пользоваться не только с компьютера, ноутбука, но и с планшета, с телефона. И мы видим, что у нас больше половины аудитории соискательской мобильна.
А со стороны работодателей ситуация другая. Из них лишь десять процентов пользуются мобильным приложением. Это связано с тем, что рабочее место профессиональных эйчаров, наверное, не телефон. Но это сказывается на их оперативности.
Если же говорить о целевой аудитории, то в первую очередь мы направляем маркетинговые усилия, связанные с умным поиском, на соискателей. Этот функционал нацелен на них: помочь проще и быстрее найти работу, сделать процесс поиска для них менее стрессовым. Ведь мы по нашим опросам видим, что для соискателей, особенно это касается «синих воротничков» в регионах, смена работы — стресс. Если говорить прямым текстом, они этого боятся. В идеале наши улучшения, наш рост количества откликов в конечном итоге изменит качество жизни соискателей. Они не будут бояться сменить работу, которая им не нравится, на которой они мало получают, на которую долго ехать, на которой что-то не устраивает, — и попробуют найти более качественную работу, все-таки на работе мы проводим почти треть жизни. И пусть у них это время уходит не на самоистязание: вот я глупый человек, работаю в странном месте, но мне тут платят деньги, хоть и небольшие.
— Вы упомянули, что в вашу аудиторию входят «синие воротнички». Но мне всегда казалось, что вы занимаетесь офисными работниками.
— Действительно, лет пять-семь назад HeadHunter позиционировался как сайт только для офисного персонала. Сейчас это не так. У нас чуть ли не основной аудиторией являются, например, водители.
— С чем это связано?
— Это связано с изменением нашей стратегии: последние несколько лет мы предоставляем клиентам-работодателям так называемое полное решение — чтобы работодатель мог полностью закрывать все вакансии у нас. То есть, если к нам приходит завод, он может найти у нас кандидатов не только таких профессий, как бухгалтер, экономист и менеджер, но и рабочих, мастеров, водителей, логистов. Для «синих воротничков» мы упрощаем интерфейс, взаимодействие с сайтом.
— Кто ваши конкуренты?
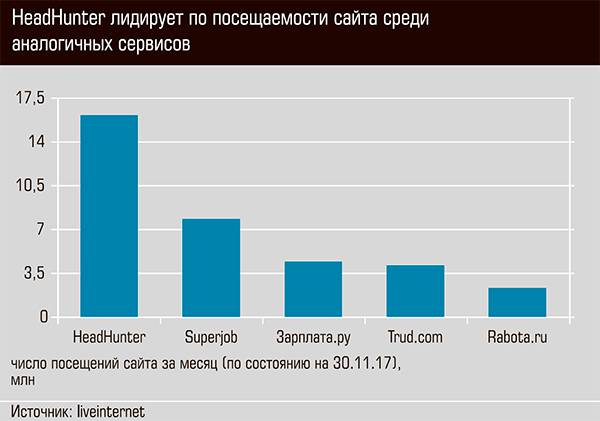
— У нас их довольно много. Среди них традиционные джоб-сайты: Rabota.ru, Superjob.ru, Job.ru и Зарплата.ру. Появились и новые с рынка классифайдов, объявлений. Например, «Авито». Для них это не основной бизнес, но одно из направлений, куда они целятся. Есть конкуренты зарубежные. Менее значимыми конкурентами являются профессиональные соцсети, хотя это, скорее, очень нишевый проект для топ-менеджеров и ИТ-сферы. Но мы себя уверенно чувствуем. Статистика показывает, что мы — лидеры и по аудитории, и по количеству резюме и вакансий.
— Насколько ваша разработка оригинальна?
— Отличный вопрос. Мы на рынке подобных разработок не знаем. Но надо понимать, что мы не научная лаборатория, сами алгоритмы не придумываем. Мы использовали для машинного обучения проверенные временем алгоритмы, которые используют и другие компании вроде Google и «Яндекса».
В чем наше собственное ноу-хау? Первое — те несколько сотен признаков, значимо влияющих на отклик, которые удалось выявить в результате нашего эксперимента и тестов. Такой информации, такого метода ни у кого нет.
Второе — наши большие данные. Мало иметь алгоритм, уметь его применять, иметь очень мощную продвинутую команду. Надо, чтобы у тебя были данные, на которых система машинного обучения научится и даст нужный результат. Здесь действует правило «размер имеет значение». Если у вас данных мало, рекомендации и поиск у вас будут некачественными. Искусственный интеллект и машинное обучение не волшебная палочка — это математика, статистика, программирование. Чтобы эти системы работали, им нужно скормить много данных. Обычно чем больше, тем точнее они работают.
Третье — то, что называется Machine Learning Pipeline, то есть инфраструктура машинного обучения. Это и модели машинного обучения, и инструменты вспомогательные, и система А/В-тестирования, которая позволяет статистически значимо выявлять эффективность изменений в системе. В России на этом поле с нами может соперничать, наверное, только «Яндекс».
— Но наверняка какие-то компании уже идут по вашим стопам?
— К сожалению, то, что мы сейчас видим на рынке «эйчартеха» и машинного обучения — это ситуация хайпа: появляется много компаний, которые хотят, используя умные и красивые слова, но еще не имея продукта, получить инвестиции. То есть такой же хайп, что и с вещами типа больших данных, блокчейна, прости господи… На нашем рынке таких компаний несколько десятков. Хотя, возможно, у некоторых из них что-то и получится. Но за последние пять лет из стартапов, создававшихся для разработки цифровых решений в сфере HR, выжили один-два, не больше.
Кроме того, большинство стартапов, так или иначе связанных с рекрутингом, работают в полулегальном режиме с точки зрения получения информации о соискателе. У нас в России есть несколько законов, регулирующих использование персональных данных и данных в целом. Нельзя просто зайти на какой-то сайт по поиску работы, скачать информацию и ее перепродавать. Или, каким-то образом получив информацию от самого соискателя, но не получив от него согласия на обработку персональных данных, с ней законно что-то делать. И у нас есть пяток стартапов, у которых очень хороший маркетинг и PR, их можно легко найти в интернете, они выступают на конференциях. Но как только юридически грамотный клиент задает вопрос: «А как у вас обстоят дела с защитой персональных данных?», они тушуются.
Медлительные — вниз
— Какие риски связаны с использованием искусственного интеллекта в рекрутинге?
— Риски, безусловно, есть. Для каких-то пользователей сервис может работать хуже. И это абсолютно нормально. Искусственный интеллект можно грубо сравнить с человеком: люди ошибаются, например, из-за того, что у них был противоречивый опыт. То же касается и машин. Но мы обязательно собираем негативную обратную связь и смотрим, действительно ли есть какие-то системные проблемы. Например, один соискатель, высококвалифицированный рабочий, пишет: «Вы мне рекомендуете такую-то вакансию, но у моей специальности аббревиатура другая, хотя и мало отличается от рекомендуемой». Такие ошибки случаются. Но для нас в первую очередь важно, что мы для подавляющего большинства аудитории, для 99 процентов, становимся лучше. И чаще всего отрицательные отзывы связаны, скорее, с чрезмерными ожиданиями от системы.
А второе, есть риски — я бы назвал это вызовами — в том, что мы учимся на данных, которые сгенерировали службы HR. Они могли ошибаться, а мы просто повторяем их поведение. Поэтому на следующий год мы запланировали ряд экспериментов, когда будем в ручном режиме некоторые параметры делать более значимыми. У нас есть несколько десятков гипотез, когда мы хотим не просто копировать поведение рекрутеров, но его как-то корректировать в то, что, как нам кажется, будет полезным для соискателей.
Приведу пример. Мы хотим, чтобы рекрутеры быстрее разбирали отклики. Нам очень важно, чтобы соискатель быстрее получил обратную связь, чтобы он понял, что его отклик не выкинули в мусорное ведро. Поэтому мы хотим изменять ранжирование вакансий в качестве одного из параметров по количеству неразобранных откликов. То есть при прочих равных, если у тебя вакансия получила сто откликов, а ты их не разбираешь, она будет потихоньку уползать вниз в поисковой выдаче. Такой же подход использует, например, компания Airbnb — крупнейший оператор сдачи квартир. Если хозяин квартиры очень долго отвечает на запросы, его квартира в выдаче опускается вниз, чтобы стимулировать ускорение коммуникации.
— Как вы будете развивать ваш сервис дальше?
— У нас наполеоновские планы. Мы видим прекрасное будущее на горизонте пяти-семи лет: рекрутментом будет заниматься ансамбль систем машинного обучения, большая система искусственного интеллекта. Потому что мы видим, что практически все задачи, когда у тебя есть данные, на основании которых нужно принять решение, можно сделать с помощью искусственного интеллекта как минимум на уровне среднего человека. А максимум, если хорошо поработать, — на уровне эксперта. Мы в следующем году будем развивать те системы, о которых я говорил. Это означает, что мы будем всякие технические штучки пробовать, уже имеющийся массив из нескольких сотен признаков поиска наращивать. У нас много идей, какие еще факторы можно использовать, как можно на эти факторы по-другому посмотреть. Ведь на тот же текст из точек в пространстве можно по-разному смотреть: насколько они близко друг к другу находятся, по-разному координаты у этих точек выставлять. Мы все это будем пробовать.
И будем развивать наработки, ставить эксперименты использования технологий искусственного интеллекта в работе с работодателями. Здесь вызовы немножко другие, чем на направлении соискателей. У нас есть очень большая база резюме: сейчас их 27 миллионов. И мы хотим разработать практически зеркальную процедуру: умный, качественный и быстрый поиск по этой базе данных, который мы также сможем поддерживать нашими рекомендациями. Несмотря на то что этот функционал будет настроен для работодателей, выигрывают и соискатели, потому что их будут быстрее приглашать на собеседование, то есть это ситуация win-win. В принципе, эти собеседования должны быть на более качественные и более подходящие вакансии.

— Каким вы видите будущее рекрутинга? Будут ли, например, чат-боты проводить собеседования?
— Тема, связанная с чат-ботами, сейчас очень популярна. Их неправильно называть искусственным интеллектом, но это не отменяет того факта, что это интересная технология.
Сейчас чат-боты вполне можно использовать для отсева явно неподходящих кандидатов. Например, вам нужно найти секретаря. Вы знаете, какие вопросы хотите секретарю задать, они определенным образом записываются в виде сценария в чат-бот, и он может проводить предварительное собеседование. Это позволяет экономить ресурсы. Но опять возникает вопрос эффективности нового инструмента. Сейчас для первичного собеседования можно сделать обычную веб-форму, где кандидат будет просто расставлять галочки и проходить тест: владение английским языком на определенном уровне, грамотная работа с Word, Excel, прочими офисными приложениями, может быть, «1С» или что-то подобное. И эта форма тоже будет с определенным процентом конвертировать людей из откликов в пройденные интервью. По-хорошему, технология чат-ботов должна увеличить этот показатель. Но пока мы знаем от наших клиентов, что зачастую им приходится после пилотного проекта отказываться от некоторых разрекламированных продуктов, поскольку конверсия низкая. А между тем за то, что вы привлекаете аудиторию с этого чат-бота, вы платите деньги. И если у него конверсия низкая, каждый соискатель, пришедший на интервью с живым человеком, стоит вам дороже.
Но это не исключает того, что в каких-то нишах проекты на чат-ботах будут весьма эффективны. Это, например, масс-рекрутинг, когда тебе надо «прогнать» большое количество людей. Не исключено также, что появятся удобные боты в мессенджерах, потому что у мессенджеров сейчас очень большая аудитория. У всех есть WhatsApp, Viber, Telegram и прочее. У них может быть ниже конверсия, но дешевле будет покупать, например, рекламу в WhatsApp и нагонять аудиторию в эту воронку.
И следующее, о чем хочется сказать: мы думаем, что — и мы видим это на других рынках — в таких ботах вполне могут появляться уже элементы искусственного интеллекта. Боты текущие — это жесткий сценарий, а следующие боты будут использовать мягкий сценарий. То есть бот сможет отклоняться от основной линии: например, ответить соискателю на вопросы по работе, сообщить, где расположен офис, обучившись на предыдущих диалогах. Все слышали о ярком событии: «Яндекс» запустил бот «Алиса» — это как раз пример такой технологии, они вполне могут через какое-то время прийти в рекрутинг.
— Из рекрутинга может окончательно вытесниться человек?
— Полностью рекрутеры точно никуда не денутся. Да, наш искусственный интеллект работает как рекрутер. Но люди нужны для постоянного мониторинга: появляются новые профессии, что-то в правилах может поменяться. Это важно отслеживать.
Точно вымрут, как динозавры, рекрутеры и эйчары, которые не умеют эффективно работать с компьютерными системами и хотя бы на базовом уровне не понимают тех вещей, о которых мы сегодня с вами говорим. У них просто нет шансов. Точно останутся люди, которые научатся работать с этими системами.
При этом мы видим, что очень хорошо автоматизируется все, что связано с линейными специалистами, массовым подбором. Хуже, когда речь заходит о среднем персонале. Практически никак не автоматизируется подбор руководителей высшего звена, топ-менеджеров и каких-то редких специалистов. Если я себе ищу главного инженера, то традиционные подходы — пока, по крайней мере, — будут работать лучше. Но если вы массово набираете продавцов в федеральную сеть, то, если вы не используете технологии, у вас стоимость подбора будет в лучшем случае на несколько десятков процентов выше, чем у конкурента, который эти технологии использует, в худшем — в несколько раз. А в случае федеральных сетей мы говорим о десятках миллионов рублей, потраченных на подбор за год.
